
Scraping ist in Zeiten des harten Wettbewerbs um die besten Platzierungen in den Google-Ergebnissen eine durchaus beliebte Methode für Webseiten-Betreiber und SEO-Experten. Jedoch gilt auch hier, dass jede Medaille zwei Seiten hat.
Lesen Sie bei uns, was Scraping überhaupt ist und welche Aspekte dabei beachtet werden sollten.

Scraping kann nützlich für SEO-Aktivitäten sein. Bild: Picabay/FirmBee
Scraping – Extraktion von Webinhalten für die weitere Verwendung
Experten sprechen zumeist von Web-Scraping oder Screen-Scraping. Gemeint ist damit das „Schürfen“ von Web-Inhalten, die dann in ähnlicher oder anderer Form weitere Verwendung finden. Die Extraktion dieser Inhalte kann manuell erfolgen, wird aber zumeist mit spezieller Software oder Bots realisiert, die in kürzester Zeit eine Vielzahl von Seiten durchsuchen können.
Scraping kann für Webseiten-Betreiber viele Vorteile generieren und dabei helfen, die eigene Plattform relevanter zu gestalten und so das eigene Ranking bei Google und Co. zu verbessern. Content, der nicht erst einmal aufwändig recherchiert und erstellt werden muss, sondern quasi „kopiert“ wird, spart natürlich Ressourcen und damit auch Geld.
Aber genau dieses Kopieren kann den engagierten Schürfern auch zum Verhängnis werden. Denn Urheberrechte sind natürlich immer zu wahren. Und davon ganz abgesehen, mag der Google-Algorithmus stumpfes Kopieren überhaupt nicht.
Scraping-Techniken
Die einfachste Möglichkeit, Scraping erfolgreich anzuwenden, sind so genannte Scraping-Tools. Dabei handelt es sich um spezielle Software, die nicht nur Inhalte, sondern auch komplette Seitenstrukturen oder gar Funktionalitäten kopieren kann. Eine andere Methode ist die http-Manipulation, mit der der Web-Content via http-Request kopiert wird.
Zu guter Letzt kann Data Mining zum Einsatz kommen. Ein Algorithmus identifiziert den Inhalt anhand des Templates und Scripts, in das er eingebettet ist. Die geschürften Daten lassen sich dann mit Hilfe eines so genannten Wrappers umwandeln und für andere Seiten zur Verfügung stellen. Data Mining findet grundsätzlich häufig im Rahmen von KI und Big Data statt und verfügt im Gegensatz zu den anderen Scraping-Methoden über eine hochkomplexe technologische Basis, die weit über das Kopieren von Web-Inhalten hinaus gehen kann.
Wer technisch weniger versiert ist oder die Investition in Tools und smarte Programmierer scheut, kopiert einfach selbst. Ganz klassisch über die Shortcuts Strg+C und Strg+V.
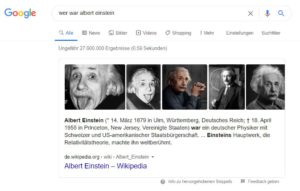
Google selbst nutzt Scraping für seine OneBox. Bild: Screenshot Google
Positive Anwendungsfälle
Wie eingangs erwähnt wird Web-Scraping häufig genutzt, um gute, fremde Inhalte zu finden, zu kopieren und für die Optimierung der eigenen Webseite zu nutzen. Das ist allerdings weder im Sinne der Urheber noch in dem von Google. Im Jahr 2012 wurde der Suchmaschinen-Riese diesbezüglich auch erstmals aktiv und sperrte bestimmte Dienste.
Tatsächlich nutzt Google aber mittlerweile auch selbst die Kopier-Methode. Beispielsweise für seine eigene Flug-Suche. Anhand der Daten der Deutschen Bahn und denen von Airlines kann der Google-Nutzer direkt über die Suchmaschine nach passenden Angeboten suchen und seine Reise planen. Zwar erfolgt die finale Buchung dann doch über die Anbieter selbst, die ersten Klicks, die die Anbieter vor Einführung dieser Funktion einheimsen konnten, gehen jedoch verloren. Gleiches gilt für die sogenannte OneBox, von SEOs häufig auch als „Platz 0“ bezeichnet. Statt die beste und relevanteste Seite zur Suchanfrage ganz oben anzuzeigen, liefert Google selbst die Antwort auf die Frage innerhalb einer kleinen Box über den weiteren Suchergebnissen.
Unter dem Strich sind das aber alles Beispiele, bei denen Scraping legal und nutzerfreundlich Anwendung findet. Anders sieht es aus, wenn Urheberrechte verletzt werden.
Negative Anwendungsfälle für Web-Scraping
Kopieren augenscheinlich findige Webseiten-Betreiber die Inhalte von „guten“ Seiten, die bessere Rankings erzielen, und veröffentlichen sie ungefragt und ohne Quellenangabe 1:1 auf ihrer eigenen Plattform, droht mächtig Ärger. Denn in diesem Fall verletzt der Kopierer die Urheberrechte. Häufig zu beobachten ist diese Praxis bei Seiten, die eine Art Lexikon oder Glossar beinhalten und sich der Einfachheit halber stumpf bei Wikipedia bedienen. Oder aber auch bei Online-Shops, die die Produktbeschreibungen der Konkurrenz einfach für sich selbst nutzen.
In diesem Fall drohen folgende Konsequenzen:
- Abmahnungen wegen Urheberrechtsverletzungen, Anzeigen, Bußgelder, etc.
- Herabstufung der eigenen Webseite durch Google, sobald der Algorithmus den „Duplicate Content“ erkennt
Zum letzten Punkt: Wenn Google eines nicht mag, dann doppelte Inhalte. Für ein gutes Ranking ist es unerlässlich, „einzigartigen Content“ bereitzustellen. Klar, der macht mehr Arbeit, aber anders geht es nicht.
Screen-Scraping der eigenen Webseite verhindern
Wenn Sie verhindern möchten, dass sich Dritte Ihre sorgfältig erstellten Inhalte zunutze machen, können Sie Maßnahmen ergreifen, die zumindest das maschinelle Web-Scraping verhindern. Hier führen gleich mehrere Wege nach Rom – beispielsweise die Einbindung von Captcha-Abfragen, eine Verstärkung der Firewall oder eine Bot-Blockade über die robots.txt.
Sie verstehen an dieser Stelle nur Bahnhof? Sie haben keine Ahnung, wie sich so etwas umsetzen lässt? Kein Problem! Für solche spezifischen Aufgaben gibt es glücklicherweise Fachleute. Sie finden solche Profis sicherlich auch unter den Experten aus dem IT-SERVICE.NETWORK. nehmen Sie Kontakt auf und lassen sich zu den verschiedenen Möglichkeiten beraten. Wir freuen uns auf Sie!

Geschrieben von
Lena Klaus arbeitet seit 2018 als freie Autorin und SEO-Expertin für das IT-SERVICE.NETWORK. Besonders die Themen rund um den digitalen Wandel und New Work haben es ihr angetan. Darüber hinaus ist die erfahrene Texterin immer wieder fasziniert davon, welche neue Methoden und Tricks Hackern und Cyberkriminellen einfallen. Seit 2013 kennt Lena Klaus die IT-Branche und… Weiterlesen
Schreiben Sie einen Kommentar
* = Pflichtfelder
Bitte beachten Sie unsere Datenschutzerklärung